
本章将通过爬取51jobs求职网站中的python职位信息来实现不同方式的数据存储的需求。
github地址———>源代码
我们先来看一下:51jobs网站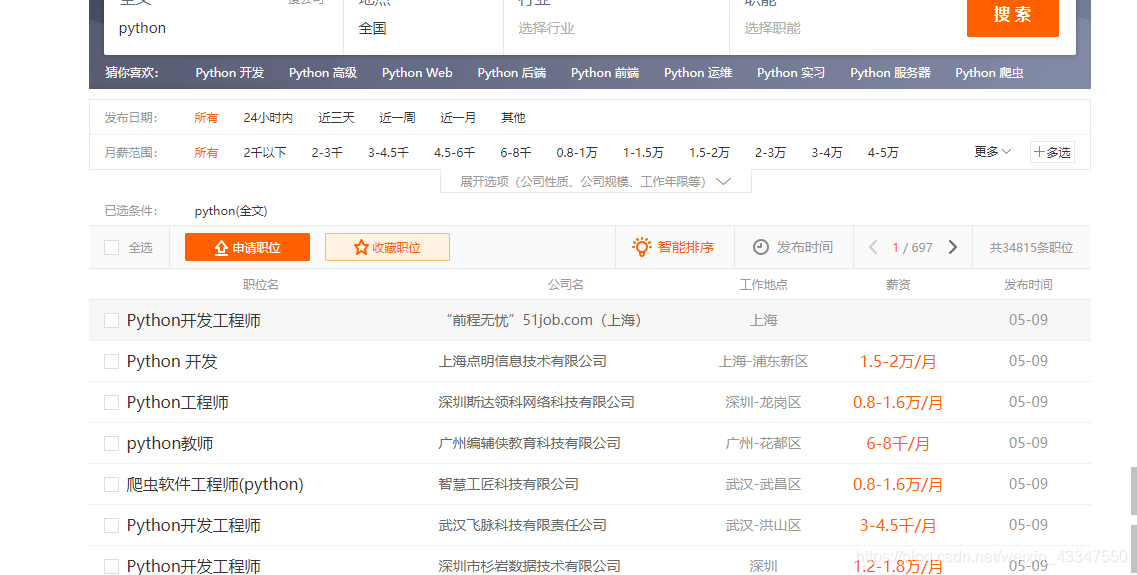
我们需要的数据有,职位名 公司名 工作地点 薪资,这四个数据。
然后我们看一下他们都在哪
发现他们都在
这里面
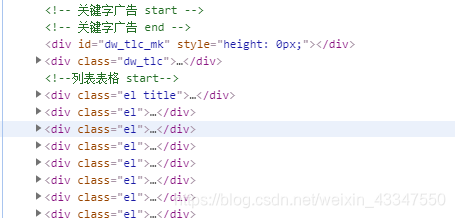
需要的数据,相应的都在这里面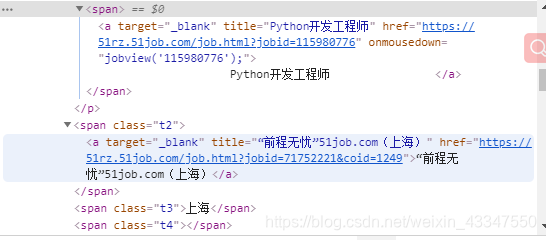
好了到这,我们已经知道了抓取的数据都在哪了。接下来我们开始写代码。
创建项目
使用命令scrapy startproject tongscrapy 来创建一个scrapy框架。
然后使用scrapy crawl py51jobs https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html 来创建一个spider项目。
完成这些后打开 pycharm,将创建的项目,添加到pycharm中。
如下图所示: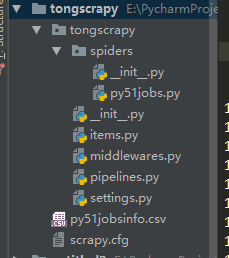
然后就是开始重写各个py文件了。
重写 py51jobs.py
1 | class Py51jobsSpider(scrapy.Spider): |
重写item.py
1 | class TongscrapyItem(scrapy.Item): |
重写pipelines.py
1 | # 数据存储在csv文件里 |
最后重写settings.py,写入mysql数据库的配置信息和相应的ITEM_PIPELINES
1 | BOT_NAME = 'tongscrapy' |
运行py51jobs.py,并输出结果:
使用代码:scrapy crawl py51jobs
运行结果为(展示最后部分):
1 | 2020-05-09 23:24:08 [scrapy.core.scraper] DEBUG: Scraped from <200 https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,4.html> |

