本章将通过爬取51jobs求职网站中的python职位信息来实现不同方式的数据存储的需求。
github地址———>源代码
我们先来看一下:51jobs网站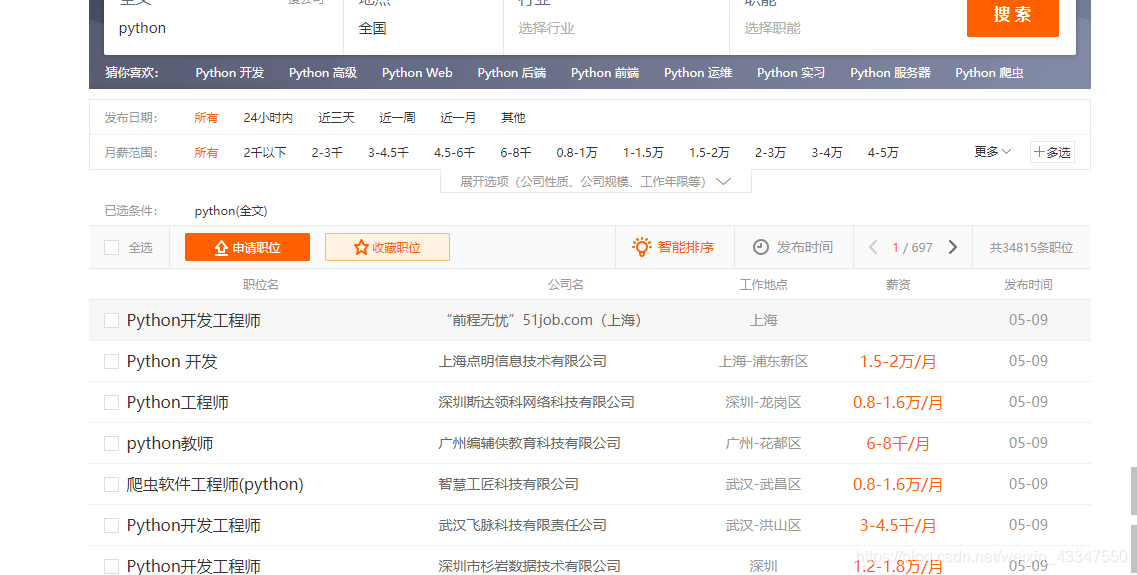
我们需要的数据有,职位名 公司名 工作地点 薪资,这四个数据。
然后我们看一下他们都在哪
发现他们都在
这里面

Not only can I write code well, but I can also swim well
!s(apply str())和!r(apply repr())可用于在格式化之前转换值。
字符串之间的区别很容易看出来(因为repr字符串将包含外部引号):
1 | 'foo {!s}'.format('bar') |
这两种方法之间的区别实际上主要取决于要格式化的对象。对于许多对象(例如那些不覆盖该__str__方法的对象),格式化输出将没有差异。
我们先看一个原始代码:
1 | import time |
看一下运算时间结果:
1 | time:8.983859300613403 |
然后我们加一行代码,再看看结果:
more >>正常步骤先上爬取效果图:
原理:从邮箱开始半自动爬取qq好友头像。
首先我们先打开网页版qq邮箱,并登陆上你的qq账户,通过qq邮箱来获取所有人的qq号。
接下来我用Google Chrome 浏览器来演示:
学python的,学过类与对象的,都会经常看到和用到__init__(self, ),__new__(cls, ),__del__(self)。
但是很多可能见过的,却不知道怎么用,或者为什么用。没有真正的了解它们。
然而其实这些就是我们学习面向对象编程语言中的构造方法和析构方法。
这三个其实还有另一种称呼叫做魔法方法.
魔法方法顾名思义,就是总是被左右各两个下划线包围的方法称为魔法方法,如init().(注:这里我不会细说魔法方法,只会针对这三个方法进行讲解。)
前言(可省略。):
哈夫曼编码可以很有效的压缩数据:通常可以节省 20%~90%的空间,具体压缩率依赖于数据的特性。我们将待压缩数据看做字符序列。根据每个字符的出现频率,哈夫曼贪心算法构造出字符的最优二进制表示。
假定我们希望压缩一个10个字符的数据文件。下表给出了文件中所出现的字符和它们的出现频率。也就是说,文件中只出现了6个不同字符,其中字符a出现了45 000次。
| | a |b |c |d |e |f |
|–|–|—-|–|—|—|—|
| 频率(千次) | 45 | 13| 12| 16| 9 | 5 |
|定长编码 | 000 |001 | 010|011 | 100 | 101 |
|变长编码 | 0 |101 |100 |111 | 1101 | 1100 |
@[TOC](list 列表常用操作汇总)
1 | list = ['a', 'b', '123', 'z', '456'] |
